Scalar graph engine, model stack, optimizer step logic, and reproducible artifacts.
From-First-Principles Deep Learning
Micrograd From Scratch
A teaching-first deep learning build that reconstructs reverse-mode autograd, MLPs, optimizers, schedulers, and a tiny training stack in pure Python.
Best validation loss of 0.000002 on the shared tiny benchmark setup.
Readable internals first. This is meant to explain training mechanics, not compete with PyTorch.
What This Project Rebuilds
- Scalar
Valuegraph objects with reverse-mode backpropagation Neuron,Layer, andMLPabstractionsSGD,Momentum, andAdamoptimizers- Learning-rate schedulers and gradient clipping support
- Mini-batch training, train/validation tracking, and benchmark artifact generation
Why It Matters
The point of the project is not novelty. The point is implementation-level understanding. Rebuilding the stack exposes how gradients flow, how optimizers actually update parameters, and what tradeoffs appear once you stop relying on framework internals.
Training Flow
Forward Pass
Build scalar graph
Build scalar graph
→
Backward Pass
Reverse-topological grad accumulation
Reverse-topological grad accumulation
→
Optimizer Step
Update parameter data
Update parameter data
→
Trainer
Batching, metrics, scheduler
Batching, metrics, scheduler
Optimizer Benchmark
Same dataset split, seed, architecture, and learning rate. Only the optimizer changes.
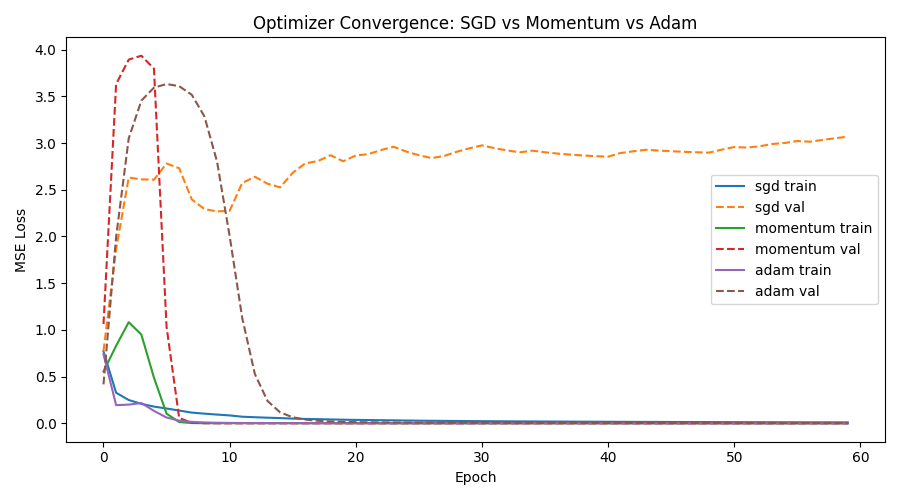
| Optimizer | Final Train Loss | Final Val Loss | Best Val Loss | Best Epoch |
|---|---|---|---|---|
| SGD | 0.010457 | 3.068415 | 0.773429 | 1 |
| Momentum | 0.000223 | 0.000002 | 0.000002 | 41 |
| Adam | 0.000408 | 0.002925 | 0.002925 | 60 |
Design Tradeoffs
- Scalar-level autograd keeps internals visible but makes training slow.
- Small abstractions keep the code readable for learning and interview discussion.
- The benchmark is intentionally tiny, so its results should be interpreted as educational, not general.
Limitations
- No tensor backend, GPU support, mixed precision, or serious throughput story.
- Numerical stability is limited compared with mature frameworks.
- This is a proof-of-understanding artifact, not a production training library.